Architecture Overview
TrainLoop Evals is designed as a comprehensive evaluation framework that captures, processes, and analyzes LLM interactions. This document explains the system architecture and how all components work together.
System Architecture
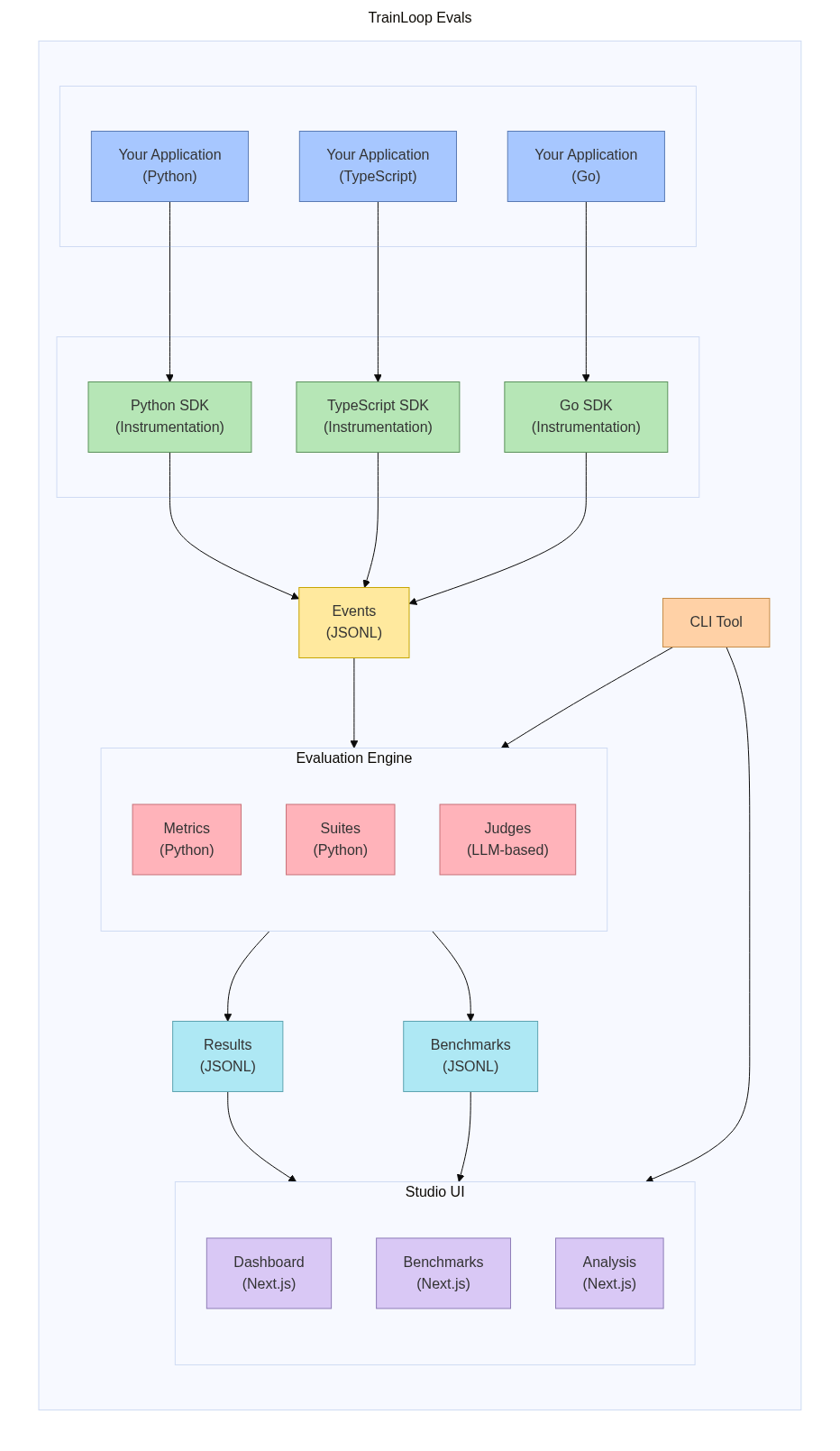
Core Components
1. Applications and SDKs
Your Applications (Python, TypeScript, Go) make LLM calls to various providers (OpenAI, Anthropic, etc.).
TrainLoop SDKs provide zero-touch instrumentation that:
- Automatically intercepts LLM API calls
- Captures request/response data transparently
- Adds metadata (timestamps, model info, custom tags)
- Writes data to JSONL event files
2. Event Storage
Events (JSONL) are the raw data collected by SDKs:
- One event per LLM interaction
- Stored as newline-delimited JSON files
- Organized by date for efficient processing
- Contains full request/response context
3. Evaluation Engine
CLI Tool processes events through:
- Metrics (Python): Functions that evaluate individual aspects of LLM output
- Suites (Python): Collections of metrics applied to specific event types
- Judges (LLM-based): AI-powered evaluation for subjective criteria
4. Results and Benchmarks
Results (JSONL) contain evaluation outcomes:
- Pass/fail verdicts for each metric
- Aggregated scores and statistics
- Metadata linking back to original events
Benchmarks (JSONL) enable model comparison:
- Re-run prompts against multiple providers
- Apply same metrics to all responses
- Generate comparative analysis
5. Studio UI
Studio UI provides interactive visualization:
- Dashboard (Next.js): Overview of evaluation results
- Benchmarks (Next.js): Model comparison interfaces
- Analysis (Next.js): Detailed exploration tools
- DuckDB Integration: SQL-based data querying
Data Flow
1. Collection Phase
Your App → SDK → Events (JSONL)
- Application makes LLM API call
- SDK intercepts the call transparently
- Request/response data is captured
- Event is written to JSONL file
2. Evaluation Phase
CLI Tool → Events → Metrics/Suites → Results (JSONL)
- CLI discovers evaluation suites
- Loads event data from JSONL files
- Applies metrics to each relevant event
- Generates results with pass/fail verdicts
3. Analysis Phase
Studio UI → Results/Events → Visualization
- Studio UI loads results and events
- DuckDB provides SQL query interface
- Interactive charts and tables display data
- Users can filter, search, and analyze
Key Design Principles
Vendor Independence
All data is stored as standard JSONL files:
- No proprietary databases
- Easy to backup and migrate
- Works with any text processing tools
- Version control friendly
Zero-Touch Instrumentation
SDKs require minimal integration:
- Single function call for Python
- Command-line flag for TypeScript
- Simple init/shutdown for Go
- No code changes to existing LLM calls
Composable Architecture
Components can be used independently:
- Use SDK without evaluation
- Run CLI without Studio UI
- Process JSONL files with custom tools
- Extend with custom metrics
Type Safety
All evaluation code is type-safe:
- Python type hints for metrics
- Structured data formats
- Clear interfaces between components
- Compile-time error detection
Deployment Patterns
1. Development Environment
Local App → Local SDK → Local Files → Local CLI → Local Studio UI
- All components run on developer machine
- Fast iteration and debugging
- No external dependencies
2. Production Environment
Production App → SDK → Cloud Storage → Scheduled CLI → Hosted Studio UI
- Events stored in cloud storage (S3, GCS)
- Evaluation runs on schedule or trigger
- Studio UI deployed as web service
- Scalable and reliable
3. CI/CD Integration
CI Pipeline → Test App → SDK → Temp Files → CLI → Pass/Fail
- Automated testing in CI/CD
- Quality gates based on evaluation results
- Fail builds on regression
- Continuous monitoring
Storage Architecture
Event Files
data/
├── events/
│ ├── 2024-01-15.jsonl # Events from January 15
│ ├── 2024-01-16.jsonl # Events from January 16
│ └── ...
Results Files
data/
├── results/
│ ├── eval_2024-01-15_14-30-25.json # Evaluation results
│ ├── benchmark_2024-01-15_15-00-00.json # Benchmark results
│ └── ...
Judge Traces
data/
├── judge_traces/
│ ├── 2024-01-15_helpful_check.jsonl # LLM Judge traces
│ └── ...
Security Architecture
Data Protection
- Encryption: Sensitive data can be encrypted at rest
- Access Control: File-based permissions
- Audit Logging: All operations logged
- Data Retention: Configurable retention policies
API Security
- Key Management: Secure storage of API keys
- Rate Limiting: Respect provider limits
- Network Security: TLS for all communications
- Error Handling: No sensitive data in logs
Performance Considerations
Scalability
- Horizontal Scaling: Multiple CLI instances
- Data Partitioning: Split by date/tag
- Caching: Avoid re-evaluation
- Batch Processing: Process multiple events together
Optimization
- Efficient Metrics: Fast evaluation functions
- Selective Evaluation: Tag-based filtering
- Incremental Processing: Only new events
- Resource Management: Memory and CPU limits
Extension Points
Custom Metrics
Write Python functions to evaluate any aspect:
def custom_metric(sample: Sample) -> int:
# Your evaluation logic here
return 1 # Pass or 0 for fail
Custom Judges
Implement domain-specific LLM judges:
def domain_judge(sample: Sample) -> int:
return assert_true(
positive_claim="Response meets domain standards",
negative_claim="Response violates domain standards"
)
Custom Integrations
Process JSONL files with external tools:
# Example: Export to data warehouse
cat events/*.jsonl | your-etl-tool | load-to-warehouse
Monitoring and Observability
Metrics Collection
- Evaluation Performance: Duration, success rate
- API Usage: Calls per provider, costs
- Data Volume: Events processed, storage used
- Error Rates: Failed evaluations, API errors
Alerting
- Quality Regression: Scores drop below threshold
- System Health: Components down or slow
- Cost Monitoring: API usage exceeds budget
- Data Issues: Missing or corrupted events
This architecture provides a robust, scalable foundation for LLM evaluation while maintaining simplicity and developer experience.