Introduction to TrainLoop Evals
Welcome to TrainLoop Evals, a comprehensive framework for automating the collection and evaluation of Large Language Model (LLM) outputs. TrainLoop Evals simplifies the process of testing and improving your AI applications with a focus on developer experience and reliability.
What is TrainLoop Evals?
TrainLoop Evals is an end-to-end evaluation framework that consists of:
- 🤖 CLI Tool (
trainloopcommand) - Python-based evaluation engine for managing evaluation workflows - 🎨 Studio UI - Next.js web interface for visualizing and analyzing evaluation results
- 📚 Multi-language SDKs - Zero-touch instrumentation libraries for Python, TypeScript, and Go
- 🔧 Registry System - Shareable metrics and evaluation suites for common use cases
Core Principles
TrainLoop Evals is built around five key principles:
🎯 Simplicity First
One environment variable, one function call, one folder of JSON files. No complex setup required.
🔄 Vendor Independence
Everything is stored as newline-delimited JSON files. No databases, no vendor lock-in.
👥 Meet Developers Where They Are
Accepts both simple declarative flows and existing bespoke evaluation loops.
🔒 Type-safe, In-code Tests
All evaluation code lives in your codebase with full type safety.
🧩 Composable, Extensible System
Helper generators follow proven patterns (similar to shadcn/ui) with trainloop add command.
Key Features
📊 Automatic Data Collection
- Zero-touch instrumentation - Add one line to capture all LLM calls
- Multi-language support - Works with Python, TypeScript/JavaScript, and Go
- Flexible tagging - Tag specific calls for targeted evaluation
- Buffering control - Configure immediate or batched data collection
🔍 Powerful Evaluation Engine
- Custom metrics - Write Python functions to evaluate any aspect of LLM output
- Test suites - Group related evaluations into logical collections
- LLM Judge - Built-in AI-powered evaluation for subjective metrics
- Benchmarking - Compare multiple LLM providers on the same tasks
📈 Rich Visualization
- Interactive Studio UI - Explore evaluation results with charts and tables
- DuckDB integration - Query evaluation data with SQL
- Real-time updates - See evaluation results as they happen
- Export capabilities - Share and analyze results outside the platform
🚀 Production Ready
- Scalable architecture - Handles large-scale evaluation workloads
- Cloud storage support - Works with S3, GCS, and Azure
- CI/CD integration - Automate evaluations in your development pipeline
- Comprehensive testing - Extensively tested across all components
Use Cases
TrainLoop Evals is perfect for:
- 🔧 Development Testing - Continuously evaluate LLM outputs during development
- 📊 A/B Testing - Compare different prompts, models, or configurations
- 🔍 Quality Assurance - Ensure LLM outputs meet quality standards before deployment
- 📈 Performance Monitoring - Track LLM performance over time in production
- 🏆 Model Comparison - Benchmark different LLM providers and models
- 🎯 Regression Testing - Detect when changes negatively impact LLM performance
How It Works
Your App + SDK → Data Collection → CLI Evaluation → Studio Visualization
↓ ↓ ↓ ↓
[LLM Calls] [events/*.jsonl] [results/*.json] [Charts & Tables]
- 🔧 Instrument - Add TrainLoop SDK to your application with minimal code changes
- 📝 Collect - Automatically capture LLM requests and responses as JSONL files
- 📊 Evaluate - Define custom metrics and test suites to assess LLM performance
- 📈 Analyze - Use the Studio UI to visualize results and identify patterns
- 🔄 Iterate - Refine your prompts and models based on evaluation insights
Architecture Overview
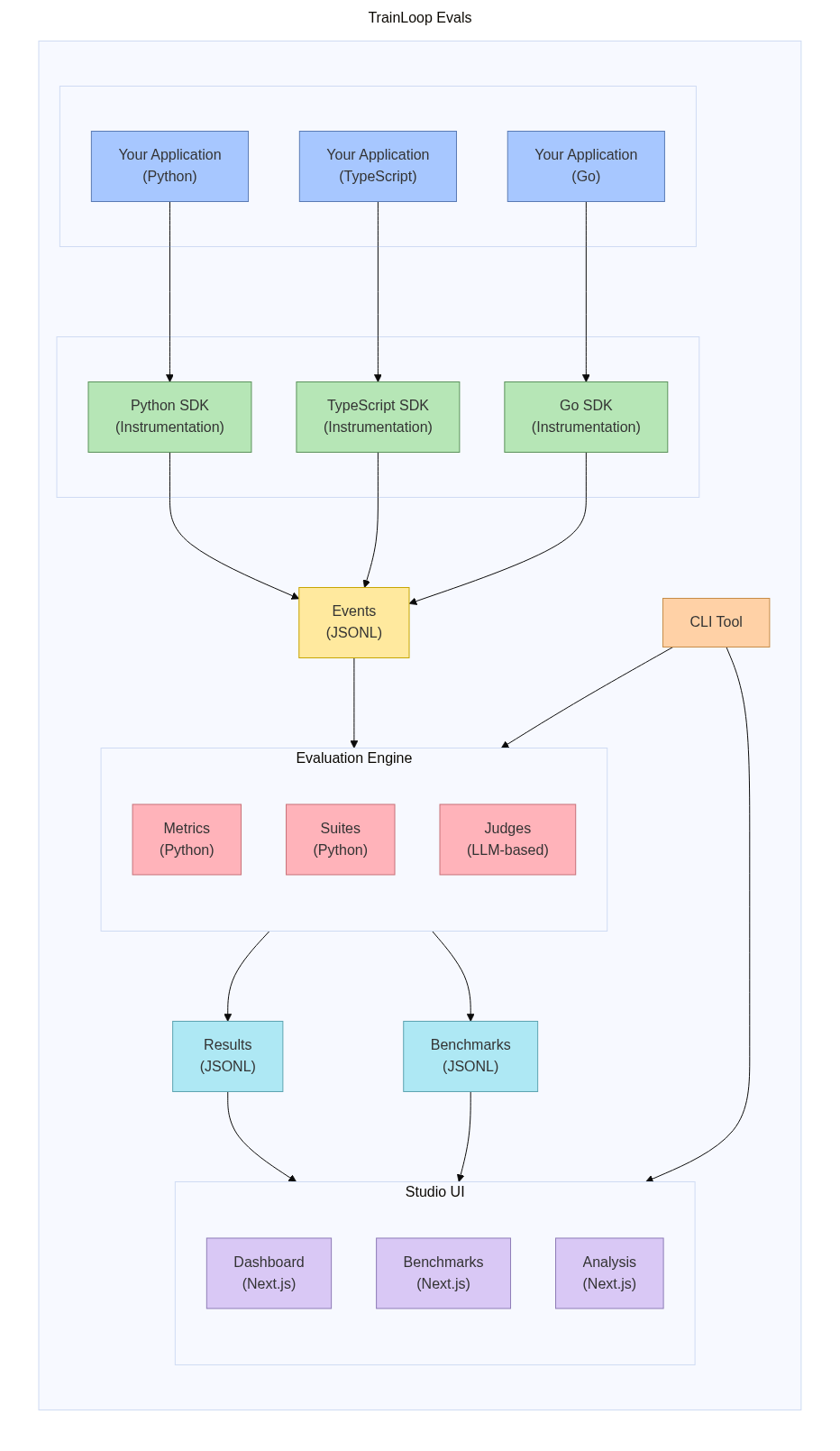
TrainLoop Evals provides a complete workflow from data collection to analysis:
- Multi-language SDKs automatically capture LLM interactions from your applications
- Event storage preserves all request/response data in JSONL format
- Evaluation engine applies custom metrics and suites to generate results
- Studio UI provides interactive visualization and benchmarking capabilities
Getting Started
Ready to start evaluating your LLM applications? Here's what you need to do:
- Install TrainLoop CLI - Get the command-line tool
- Follow the Quick Start Guide - Set up your first evaluation
- Explore the Guides - Learn advanced features and best practices
- Check the Reference - Detailed API documentation
Examples & Demos
Want to see TrainLoop Evals in action?
📚 Working Examples
Complete code examples in multiple languages:
- Python Examples - Complete Python implementation with Poetry
- TypeScript/JavaScript Examples - Both TypeScript and JavaScript versions
- Go Examples - Go implementation with modules
🎮 Live Demos
- Demo Repository - Complete chat UI example implementation
- Live Demo - Interactive demo deployment
Community and Support
- GitHub Repository - Source code and issues
- Contributing Guide - How to contribute
- DeepWiki - Chat directly with the codebase instead of reading docs.
- License - MIT License
Get started today and transform how you evaluate and improve your LLM applications!